 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe predictability of letters in written english
Oct 26, 2007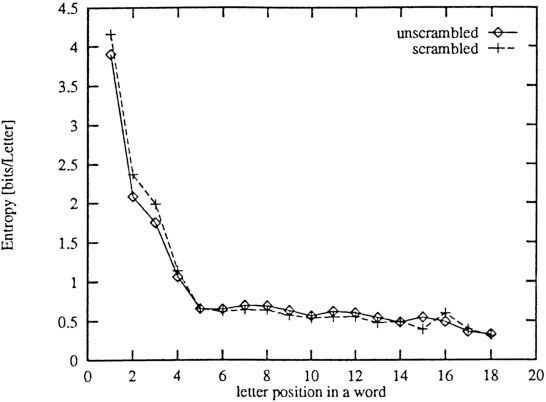
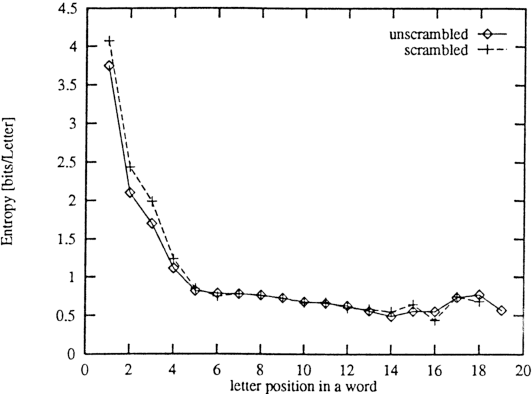
We show that the predictability of letters in written English texts depends strongly on their position in the word. The first letters are usually the least easy to predict. This agrees with the intuitive notion that words are well defined subunits in written languages, with much weaker correlations across these units than within them. It implies that the average entropy of a letter deep inside a word is roughly 4 times smaller than the entropy of the first letter.
* 3 pages, 4 figures
Entropy estimation of symbol sequences
Mar 21, 2002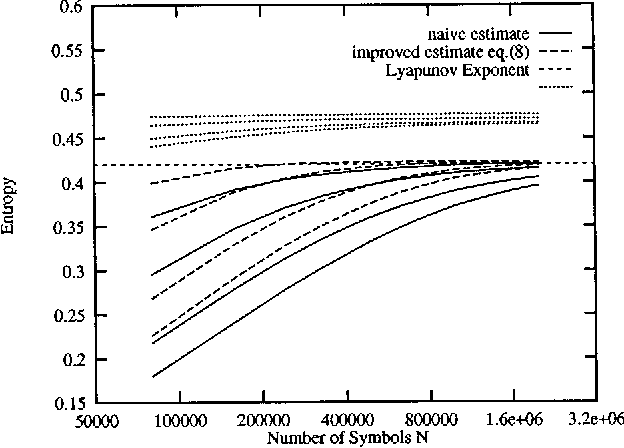
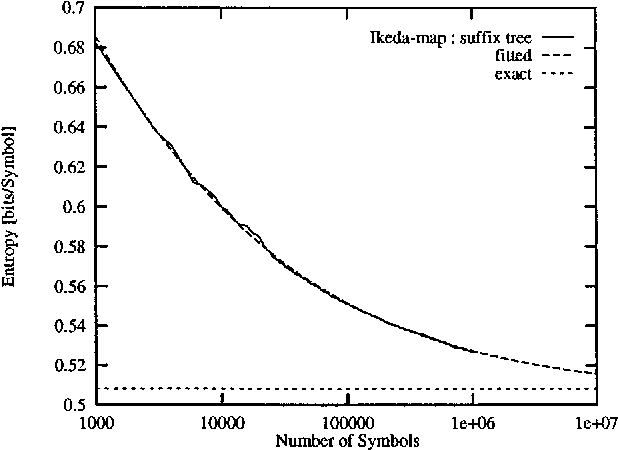
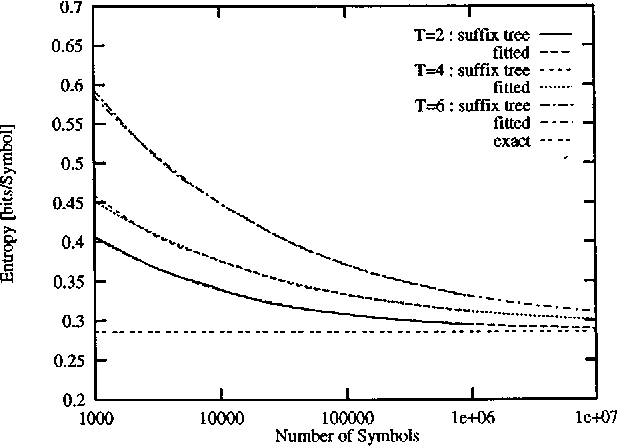
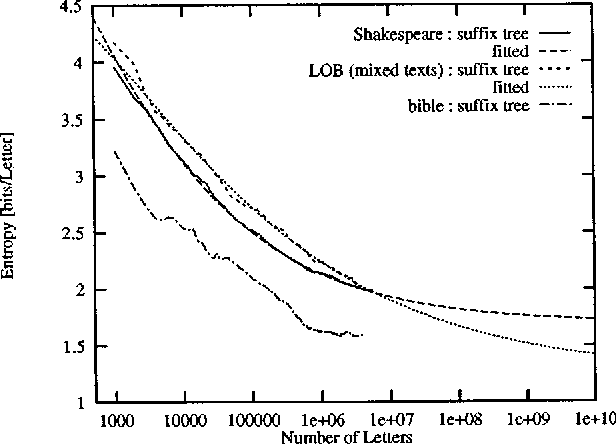
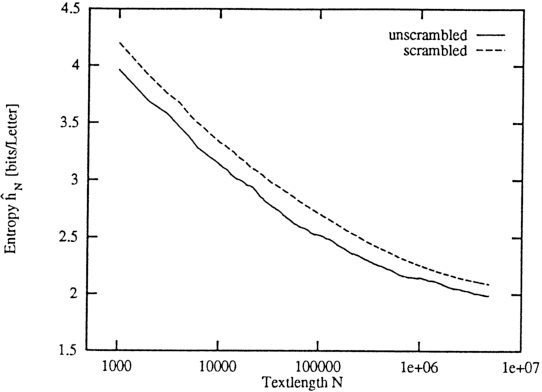
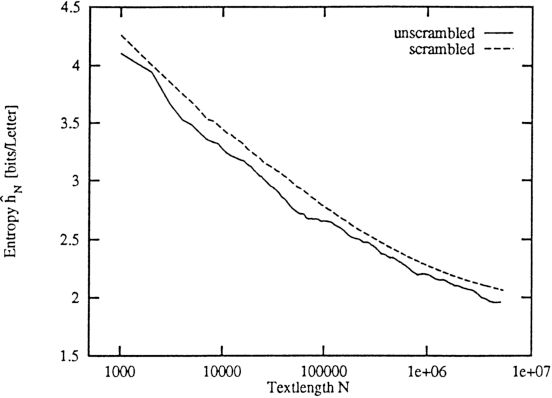
We discuss algorithms for estimating the Shannon entropy h of finite symbol sequences with long range correlations. In particular, we consider algorithms which estimate h from the code lengths produced by some compression algorithm. Our interest is in describing their convergence with sequence length, assuming no limits for the space and time complexities of the compression algorithms. A scaling law is proposed for extrapolation from finite sample lengths. This is applied to sequences of dynamical systems in non-trivial chaotic regimes, a 1-D cellular automaton, and to written English texts.
* 14 pages, 13 figures, 2 tables